Browser and Network#
Browser Kernel#
Rendering Engine#
Used to interpret web syntax and render it on the web page. Responsible for displaying the requested content. If the requested content is HTML, it is responsible for parsing the HTML and CSS content and displaying the parsed content on the screen.
Common rendering engines can be divided into four types: Trident, Gecko, Blink, Webkit.
JS Engine#
Used to parse and execute JavaScript code. The JavaScript interpreter for Chrome is V8.
The Process from Entering URL in Address Bar to Page Rendering#
- Parse the URL into an IP address, first checking the cache; if not found, perform DNS resolution to obtain the IP from the domain name server.
- Establish a TCP connection.
- SSL has a verification process.
- Send an HTTP request.
- Receive the resource document in response from the server.
- Construct the DOM tree and CSSOM tree, layout, and then render.
- Display the page.
HTTP and HTTPS#
HTTP#
HTTP: Hypertext Transfer Protocol, located at the application layer, based on TCP/IP protocol, using stateless connections.
Request Fields#
- User-agent, browser identifier
- Authorization, authentication information, can include token
- Origin, backend can determine, access-control-allow-origin
- Cookie
- Cache-control: includes max-age, determines whether to hit strong cache
- If-Modified-Since, 304, negotiated cache
- If-None-Match, 304
Response Fields#
- set-cookie,
Set-Cookie: UserID=JohnDoe; Max-Age=3600; Version=1 - ETag, an identifier for a specific version of a resource, usually a message hash
ETag: "737060cd8c284d8af7ad3082f209582d" - Expires, specifies a date/time; if exceeded, the response is considered expired,
Expires: Thu, 01 Dec 1994 16:00:00 GMT - Last-Modified, the last modification date of the requested object,
Last-Modified: Tue, 15 Nov 1994 12:45:26 GMT
Status Codes#
1: Message, temporary response, indicating that the request has been accepted and needs further processing.
2: Success, indicating that the request has been successfully received, understood, and accepted by the server.
3: Redirection, the subsequent request address (redirection target) is specified in the Location field of this response.
The requested resource has been permanently moved to a new location, and any future references to this resource should use one of the URIs returned in this response.
Requests the client to perform a temporary redirection (the original description phrase is "Moved Temporarily").
The response corresponding to the current request can be found at another URI.
- 304 Not Modified
Not modified. The requested resource has not been modified; when the server returns this status code, no resource will be returned.
Indicates that the resource has not been modified since the version specified by the If-Modified-Since or If-None-Match parameters in the request header. In this case, since the client still has a previously downloaded copy, there is no need to retransmit the resource.
Note: Related to negotiated caching.
- 305 Use Proxy
The requested resource must be accessed through the specified proxy. The Location field will provide the URI information of the specified proxy, and the recipient needs to send a separate request through this proxy to access the corresponding resource.
4: Client Error
- 400 Bad Request
The server cannot or will not process the request due to a clear client error (e.g., malformed request syntax, too large size, invalid request message, or deceptive routing request).
- 401 Unauthorized
Unauthenticated, similar to 403 Forbidden.
- 404 Not Found
- 405 Method Not Allowed
- 418 I’m a teapot
5: Server Error
- 500 Internal Server Error
A generic error message, indicating that the server encountered an unexpected condition that prevented it from fulfilling the request. No specific error information is provided.
- 502 Bad Gateway
The server acting as a gateway or proxy received an invalid response from the upstream server while attempting to fulfill the request.
- 503 Service Unavailable
The server is currently unable to handle the request due to temporary maintenance or overload. This condition is temporary and will be resolved after some time.
- 504 Gateway Timeout
The server acting as a gateway or proxy did not receive a timely response from the upstream server (the server identified by the URI, such as HTTP, FTP, LDAP) or auxiliary server (e.g., DNS) while attempting to fulfill the request.
HTTPS#
Built on top of HTTP with the addition of the SSL protocol, it is the secure version of HTTP.
Improvements in HTTP/2.0#
- Based on HTTPS, security is more guaranteed.
- Uses binary format, which is more universal than the previous text-based transmission.
- Multiplexing, an enhancement of the previous long connection.
GET, POST, PUT, DELETE, OPTIONS, TRACE, CONNECT#
Request Types#
- GET: Request resource, can use cache.
- POST: Submit data, POST generates two TCP packets; the browser first sends the header, the server responds with 100 continue, and then the browser sends data, the server responds with 200 ok (returns data), cannot use cache.
- PUT: Update resource.
- DELETE: Delete resource.
- OPTIONS: Returns the HTTP request methods supported by a resource.
- TRACE: Echoes the request received by the server, mainly used for testing or diagnosis.
- CONNECT: Reserved for proxy servers that can change the connection to a pipeline mode in HTTP/1.1 protocol.
Idempotence#
Reference: MDN
An HTTP method is idempotent if executing the same request once has the same effect as executing it multiple times, and the server's state remains the same. In other words, idempotent methods should not have side effects (except for statistical purposes). Under correct implementation conditions, methods such as GET, HEAD, PUT, and DELETE are all idempotent, while the POST method is not. All safe methods are also idempotent.
Idempotence only relates to the actual state of the backend server, and the status codes received for each request may not be the same. For example, the first call to the DELETE method may return 200, but subsequent requests may return 404. The implication of DELETE is that developers should not use the DELETE method to implement a RESTful API that has the function of deleting the last entry.
RESTful Specification#
Use URLs to refer to resources and request types to refer to actions.
Ajax, Fetch, and Axios#
Ajax#
Implemented using XMLHttpRequest
Characteristics:
- Can encounter XSS, CSRF attacks.
- It is designed for MVC programming, which does not conform to the current front-end MVVM trend.
- Developed based on native XHR, the architecture of XHR itself is unclear, and there are already alternatives like fetch.
Fetch#
Fetch is an alternative to XHR, introduced with ES6, using the promise object in ES6, provided natively by JS, without using the XMLHttpRequest object.
Characteristics:
- Conforms to separation of concerns, without mixing input, output, and state tracked by events in one object.
- Better and more convenient syntax.
- More low-level, providing rich APIs (request, response).
- Detached from XHR, a new implementation method in ES specifications.
- Fetch only reports errors for network requests; it treats 400 and 500 as successful requests, requiring encapsulation for handling.
- Fetch does not include cookies by default; configuration options need to be added.
- Fetch does not support aborting and does not support timeout control; using setTimeout and Promise.reject for timeout control does not prevent the request process from continuing to run in the background, causing waste.
- Fetch cannot natively monitor the progress of requests, while XHR can.
fetch(url, {
body: JSON.stringify(data), // must match 'Content-Type' header
cache: 'no-cache', // *default, no-cache, reload, force-cache, only-if-cached
credentials: 'same-origin', // include, same-origin, *omit
headers: {
'user-agent': 'Mozilla/4.0 MDN Example',
'content-type': 'application/json'
},
method: 'POST', // *GET, POST, PUT, DELETE, etc.
mode: 'cors', // no-cors, cors, *same-origin
redirect: 'follow', // manual, *follow, error
referrer: 'no-referrer', // *client, no-referrer
})
.then(response => response.json()) // parses response to JSON
}
Axios#
Axios is a promise-based HTTP client for browsers and Node.js, essentially a wrapper around the native XHR, but it is a promise implementation version that conforms to the latest ES specifications.
- Supports the Promise API.
- Provides some interfaces for concurrent requests (important, facilitates many operations).
- Creates XMLHttpRequests in the browser. In Node.js, it creates HTTP requests (highly automated).
- Supports intercepting requests and responses.
- Automatically converts JSON data.
- Client-side supports defenses against CSRF, XSRF.
Differences Between Fetch and Ajax#
- When receiving an HTTP status code that represents an error, the Promise returned from
fetch()will not be marked as reject but as resolve (the returned value'sokproperty is set to false); it will only be marked as reject in case of network failure or if the request is blocked. fetch()can accept cross-origin cookies; you can also usefetch()to establish cross-origin sessions.fetchwill not send cookies unless you use the credentials initialization option.
Reasons for Fetch Sending 2 Requests#
When using fetch for a POST request, the first request sends an OPTIONS request to ask the server if it supports that type of request; if the server supports it, the actual request is sent in the second request.
Strong Cache and Negotiated Cache#
Flowchart#
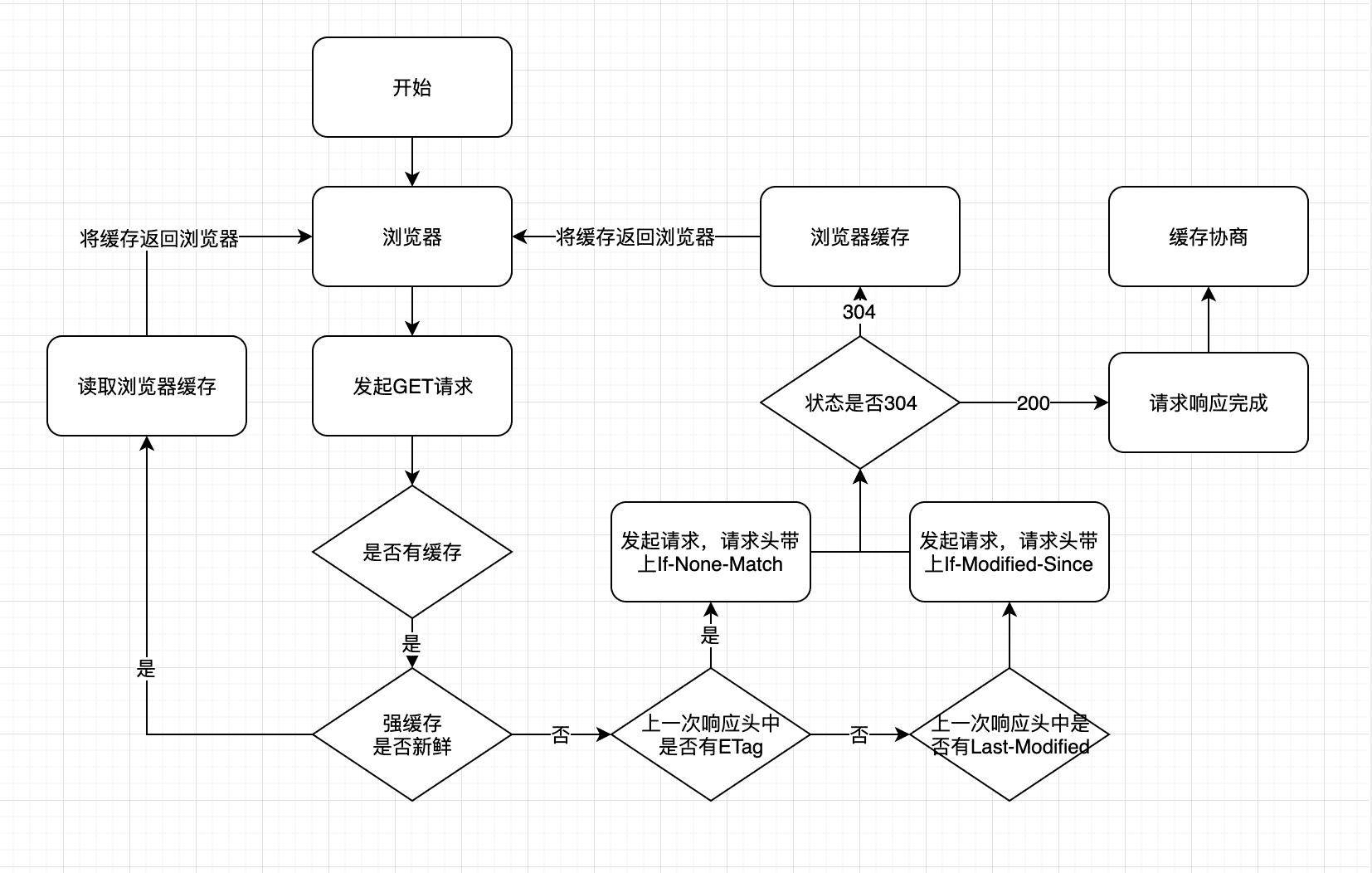
Cache#
Caching is a technique for saving copies of resources and using that copy directly on the next request. When the web cache finds that the requested resource has been stored, it intercepts the request and returns a copy of that resource without re-downloading it from the origin server.
Benefits: Relieves server-side pressure and improves performance (the time taken to obtain resources is shorter).
Tells the browser that it can directly obtain resources from the cache before the agreed time without going to the server to fetch them.
The HTTP caching mechanism is mainly set in the HTTP response headers, with relevant fields being Expires, Cache-Control, Last-Modified, Etag.
Strong Cache (Expiration Time)#
The browser does not send any requests to the server, directly reads files from the local cache and returns them.
Cache-Control (higher priority): When set to max-age=300, it means that if the resource is loaded again within 5 minutes of the correct return time, it will hit the strong cache.
Expires: Expiration time; if a time is set, the browser will read the cache directly within the set time and will not request again.
Negotiated Cache (Modification Time)#
When the resource expires, a request is sent to the server, which determines whether to hit the negotiated cache based on the request header parameters. If it hits, it returns a 304 status code and tells the browser to read the resource from the cache; otherwise, it returns a 200 status code and the new resource.
- Negotiated cache identifier 1, with a hash value of the timestamp: etag/if-none-match
When the resource expires, if the browser finds an Etag in the response header, it will include the if-none-match request header (with the value being the Etag value) when requesting the server again. The server will compare the request and decide whether to return a new page 200 or 304.
- Identifier 2, the latest modification time: Last-modified/if-modify-since
When the resource expires (the browser determines that the max-age marked by Cache-Control has expired), if the response header has a Last-Modified declaration, it will include the if-modified-since header when requesting the server again, indicating the request time. The server will compare the if-modified-since with the last modification time of the requested resource (Last-Modified); if the last modification time is newer (greater), it indicates that the resource has been modified, and it will return the latest resource, HTTP 200 OK; if the last modification time is older (less), it indicates that the resource has not been modified, responding HTTP 304 to use the cache.
Cache-Control#
- max-age: Maximum effective time.
- no-cache: Do not use strong cache; needs to verify with the server whether the cache is fresh.
- no-store: Do not use cache, including strong cache and negotiated cache.
- public: All content can be cached, including client and proxy servers, such as CDN.
- private: All content can only be cached by a single user, i.e., the client; proxy servers cannot cache. This is the default value.
Fields#
- name
- value
- size
- domain
- path
- expires/max-age: Expiration time
- http: httponly, cannot be accessed through document.cookie
- secure: Set whether this cookie can only be transmitted by HTTPS.
Cookie and Session#
Purpose: Due to the statelessness of HTTP (the current request and the previous request have no relation, are not recognized, and have no association), cookies and sessions were created to allow all web pages under a certain domain name to share certain data.
Cookies are user passports, stored on the client side, and attached when sending requests. Sessions are like user information files, containing user authentication information and login status, stored on the server side.
Using Cookie and Session Together#
- The client sends an HTTP request to the server.
- After the server receives the request, it establishes a session and sends back an HTTP response to the client, with the set-cookie header containing the sessionid.
- After the client receives the response, it will automatically add the cookie to the request header in subsequent requests.
- The server receives the request, parses the cookie, and after successful verification, returns the request to the client.
Using sessions only requires saving an ID on the client side, while a large amount of data is stored on the server side, putting pressure on the server.
Using cookies without sessions means that all account information is stored on the client side, and once hijacked, all information will be leaked. Additionally, the amount of data on the client side increases, which also increases the amount of data transmitted over the network.
Token#
A stateless authentication method on the server side. A token is like a token, stateless, and user information is encrypted into the token. The server can know which user it is after decrypting the token. Developers need to add it manually.
Tokens are generally stored on the client side in localStorage, cookies, or sessionStorage. On the server side, they are generally stored in a database.
The authentication process of a token is similar to that of a cookie.
- The user logs in, and upon success, the server returns the token to the client.
- After the client receives the data, it stores it on the client side.
- The client accesses the server again, placing the token in the headers.
- The server uses a filter to verify. If the verification is successful, it returns the requested data; if it fails, it returns an error code.
Advantages of Using Token Instead of Cookie + Session#
- Avoid CSRF attacks.
If a user logs into a banking webpage while also logging into a malicious webpage, the attacker places a form on the webpage that submits to http://www.bank.com/api/transfer with the body count=1000&to=Tom. If using session + cookie, the POST request initiated by the form is not restricted by the browser's same-origin policy and can use cookies from other domains to send POST requests, resulting in a CSRF attack. At the moment of the POST request, the cookie will be automatically added to the request header by the browser. However, tokens are specifically designed by developers to prevent CSRF; the browser will not automatically add them to the headers, and attackers cannot access the user's token, so the submitted form cannot pass through server filtering, thus preventing the attack.
- Token is a stateless authentication method on the server side, while cookie + session is stateful. (The so-called stateless means that the server does not save any data related to identity authentication.)
JWT#
Header + Payload + Signature
// javascript
var encodedString = base64UrlEncode(header) + '.' + base64UrlEncode(payload);
var signature = HMACSHA256(encodedString, 'secret'); // TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ, salted secret combination encryption
// Connect these three parts into a complete string to form the final jwt:
In client applications: generally, add Authorization to the request header, with the Bearer label.
The process is the same as that of a token.
Disadvantage: Once a JWT is issued, it remains valid until expiration unless the server deploys additional logic. JWT itself contains authentication information; once leaked, anyone can obtain all permissions of that token.
Why Cookies and Tokens Are Both Stored in Headers, and Why Tokens Are Not Hijacked?#
- Cookies
Attackers can obtain the user's cookie through XSS and then forge the cookie.
Through CSRF, under the same browser, the browser automatically adds the cookie feature.
By using the method of user website - attacker website - attacker requesting the user website, the browser will automatically add the cookie.
- Tokens
Will not be automatically added by the browser. Problem 2 is solved.
Tokens are issued to the client inside the JWT and do not necessarily need to be stored anywhere. They cannot be directly accessed through document.cookie. By using JWT + IP, it can prevent being hijacked; even if hijacked, it is an invalid JWT.
Browser Storage Methods: Cookie, SessionStorage, LocalStorage#
Common point: All stored on the browser side.
Differences:
-
Cookies can be passed back and forth between the browser and the server, while the other two are only saved locally.
-
The size of the data that can be stored is different; cookie data cannot exceed 4k, while the remaining two can store about 5M.
-
The expiration time is different; sessionStorage becomes invalid when the browser is closed, localStorage remains valid indefinitely and needs to be manually cleared, while cookies remain valid within their expiration time.
-
The scope is different; localStorage and cookies are shared across all same-origin windows, while sessionStorage is private to a specific window.
Cross-Page Communication#
Same-origin pages (not in the same tab): can use LocalStorage.
Cross-origin pages: iframe, postMessage.
After H5, the window.postMessage() method was added to the window, where the first parameter is the data to be sent, and the second parameter is the domain name.
Doctype#
Declared at the very beginning of the document, telling the server how to render the page (e.g., h5).
The running modes are: strict mode (the highest version supported by the browser), and quirks mode (backward compatibility).
XSS#
Cross-Site Scripting attack refers to an attacker injecting malicious code into a webpage, attacking users while they browse the webpage.
Types:
- Reflected: The attack code is placed in the request parameters of the URL.
- Stored: The attacker inputs some data and stores it in the database, attacking other visitors when they see it.
- DOM-based: The attacker injects malicious scripts into the user's page through various means.
Handling:
- set-cookie: httponly, prohibits JavaScript scripts from accessing cookies; secure - this attribute tells the browser to send cookies only when the request is HTTPS.
- Input validation: Any user input should be checked, filtered, and escaped.
- Output validation.
CSRF#
Cross-Site Request Forgery
As discussed when talking about tokens.
There are three main strategies to defend against CSRF attacks:
- Verify the HTTP Referer field.
- Add a token to the request address and verify it.
- Customize attributes in the HTTP header and verify them.
addEventListener#
addEventListener(event, function, useCapture)
Where event specifies the event name; function specifies the function to be executed when the event is triggered; useCapture specifies whether the event is executed in the capturing or bubbling phase.
Cross-Origin#
See: Reference
- postMessage cross-origin: one of the window properties that can operate across origins.
- CORS: The server sets Access-Control-Allow-Origin, and the front end does not need to set it; if cookies are to be sent with the request, both the front end and back end need to be set.
Access-Control-Allow-Origin *;Access-Control-Allow-Methods "POST, GET, OPTIONS";Access-Control-Allow-Headers "Origin, Authorization, Accept";Access-Control-Allow-Credentials true;- Proxy cross-origin: Start a proxy server to achieve data forwarding.
- JSONP: The link in the src attribute of the script tag can access cross-origin JS scripts. Utilizing this feature, the server no longer returns data in JSON format but instead returns a piece of JS code that calls a certain function, which is invoked in the src, thus achieving cross-origin. For example:
script.src = http://another.com/weather.json?callback=gotWeather;requires backend cooperation.
Checking Website Performance#
Detecting page load time.
-
Passive detection: Set detection scripts on the page, record data when users visit the webpage, and send it back to the database for analysis.
-
Active monitoring: Build a distributed environment to simulate user visits to the page, actively collect data, and analyze it.
Front-End Optimization#
- Reduce the number of requests: Merge resources, reduce the number of HTTP requests.
- Speed up requests: Pre-resolve DNS, CDN distribution.
- Use caching.
- Speed up rendering: Loading order (JS at the end), SSR, use GPU.
Screen Jitter#
Causes:
- Memory overflow.
- Resources too large.
- Resource loading.
- Canvas drawing frame rate.
Methods:
- Recycle and destroy objects as they leave the visible area of the screen.
- Choose smaller resources, e.g., images, using high clarity for nearby ones and low clarity for distant ones.
- Preload.
- Most displays refresh at a frequency of 60 times/s, so the drawing interval for each frame of the game needs to be less than 1000/60=16.7ms to avoid feeling laggy.
JS Loading Process Blocking, Solutions#
- Set the async attribute of the script tag for asynchronous execution.
- Set the defer attribute; the script will execute when the page parsing is complete.
BOM#
Browser Object Model, it allows JavaScript to "talk" to the browser. The window object is supported by all browsers. It represents the browser window.
Top-Level Object#
- Browser: window/self
- Web Worker: self
- Node: global
- ES5: The top-level object's properties are equivalent to global variables.
- ES6: globalThis.
This#
To ensure that the same code can access the top-level object in various environments, the this variable is generally used, but it has limitations.
-
In the global environment,
thisreturns the top-level object. However, in Node modules, it returns the current module, and in ES6, it returns undefined. -
In a function,
thisreturns the object when run as an object method, or the caller; when run purely as a function, it points to the top-level object. -
ES2020 introduced the globalThis object, which points to the global environment's
thisin any environment.
CSS and HTML#
DOM#
DOM (Document Object Model)
Document#
Finding#
-
document.getElementById(id) -
document.getElementsByClassName(class) -
document.getElementsByTagName(tag) -
document.querySelector(selectors)
Represents the first element in the document that matches a specified group of CSS selectors, an HTMLElement object. If no match is found, it returns null.
var el = document.querySelector("div.user-panel.main input[name='login']");
Here, a div element with class attributes "user-panel main" contains an input element with name attribute "login".
-
querySelectorAll(), a list of all elements that match the specified selector. -
ParentNode.firstElementChild, returns the first child element or null. -
ParentNode.lastElementChild. -
node.parentNode.
Creating#
Creates a new element with the given tag name tagName.
node.cloneNode(deep)
Returns a copy of the node that calls this method. deep, an optional parameter, indicates whether to perform a deep clone; if true, all descendant nodes of this node will also be cloned; if false, only this node itself will be cloned.
Adding#
parentNode.append(node|str)
Inserts a group of Node objects or DOMString objects after the last child node of ParentNode. The inserted DOMString object is equivalent to a Text node.
-
The
ParentNode.prependmethod can insert a series ofNodeobjects orDOMStringobjects before the first child node of the parent node. -
node.appendChild(node)
Appends a node to the end of the list of child nodes of the specified parent node.
If the node to be inserted already exists in the document tree, appendChild() will only move it from its original position to the new position (there is no need to remove the node to be moved beforehand). This means that a node cannot appear in different places in the document at the same time.
If a node already has a parent node, it will be removed first and then inserted into the new position when passed to this method.
To keep a node that is already in the document, you can first use the Node.cloneNode() method to create a copy of it and then append the copy to the target parent node. Note that a copy made with cloneNode will not automatically stay in sync.
【Differences with Node.appendChild()】
ParentNode.append()allows appendingDOMStringobjects, whileNode.appendChild()only acceptsNodeobjects.ParentNode.append()has no return value, whileNode.appendChild()returns the appendedNodeobject.ParentNode.append()can append multiple nodes and strings, whileNode.appendChild()can only append one node.
Deleting#
parent.removeChild(child)
Deletes a node based on the parent node. Although the deleted node is no longer in the document tree, it is still in memory and can be added back to another location at any time.
Getting Child Nodes#
node.children(), returns a Node's childelements, which is a dynamically updatedHTMLCollection.
CSS Selectors#
Basic Selectors#
- Universal Selector:
* {} - Element (Type) Selector:
p {} - Class Selector:
.class {} - ID Selector:
#id {} - Attribute Selector:
[attr=value] {}
Grouping Selectors#
- Selector list with
,:div, span {}
Combinators (Relationship Selectors)#
- Descendant Combinator:
div span {} - Direct Child Combinator:
div>span {} - General Sibling Combinator:
A~B {} - Adjacent Sibling Combinator:
A+B {} - Column Selector:
col || td
Pseudo-Selectors#
- Pseudo-Class:
a:visited {}, matches all<a>elements that have been visited. Supports selecting elements based on state information. - Pseudo-Element:
p::first-line, matches the first line of all<p>elements. Pseudo-selectors are used to represent entities that cannot be expressed with HTML semantics.
CSS Specificity#
Increasing order:
- Type Selector (e.g.,
h1) and Pseudo-Elements (e.g.,::before) - Class Selector (e.g.,
.example), Attribute Selector (e.g.,[type="radio"]), and Pseudo-Class (e.g.,:hover) - ID Selector (e.g.,
#example).
Styles with the !important flag have the highest priority;
Universal Selector (universal selector) (*) Combinators (+, >, ~, ' ', ||) and Negation Pseudo-Class (:not()) do not affect specificity.
When the source of styles is different, the order of specificity is: inline styles > internal styles > external styles > browser user-defined styles > browser default styles.
Box Model#
Content-Padding-Border-Margin#
- Standard (W3C) Box Model: width = content
- IE Box Model: width = content + padding + border
Content size is adaptive.
Using Box-Sizing to Set#
box-sizing: Specifies the two adjacent boxes with borders, syntax is box-sizing: content-box/border-box/inherit.
content-box: Width and height apply to the element's content box, drawing the element's padding and border outside the width and height.
border-box: The width and height set for the element determine the element's border box.
inherit: Inherit the box-sizing of the parent element.
Overflow#
The CSS property overflow defines what should happen when an element's content is too large to fit in the block formatting context.
- visible: Default value. Content will not be clipped and will render outside the element's box.
- hidden: Content will be clipped, and the rest of the content will be invisible.
- scroll: Content will be clipped, and the browser will display a scrollbar to view the rest of the content.
- auto: Determined by the browser; if content is clipped, a scrollbar will be displayed.
For overflow to take effect, the block-level container must have a specified height. All except visible trigger BFC.
Background-Size#
Used to adjust the width and height of background images, allowing for enlargement and reduction (because the default image layout is tiled according to its size).
background-size: 300px 150px; // Width and height, forced conversion
background-size: contain; // Ensure both dimensions (image width and height) are less than or equal to the corresponding dimensions of the container.
background-size: cover; // Ensure both dimensions (image width and height) are greater than or equal to the corresponding dimensions of the container.
Background-Origin#
Animation#
Transitions from one CSS style configuration to another CSS style configuration.
Two parts: style rules describing the animation, and keyframes used to specify the styles at the start, end, and intermediate points of the animation.
p {
animation-duration: 3s; // Duration
animation-name: slidein; // Animation name
background: red;
animation-iteration-count: 2; // Set the number of runs; infinite is the default value, or you can write infinite directly.
animation-direction: alternate; // Play back and forth instead of starting over.
}
@keyframes slidein {
from {
// Represents 0%
margin-left: 100%;
width: 300%;
}
50% {
font-size: 300%;
}
to {
// Represents 100%
margin-left: 0%;
width: 100%;
}
}
Transform#
Box-Sizing#
Content size is adaptive.
- box-sizing: content-box;
Indicates the standard W3C box model, width = content;
- box-sizing: border-box
Indicates the IE box model, width = border + padding + content.
Border-Radius#
- Borders:
border-radius,box-shadow, etc.;
Draw a Triangle#
<div id="demo"></div>
#demo{ width:0px; height:0px; border:40px solid transparent; border-bottom:80px solid red; }
Vertical Centering#
#box {
width: 300px;
height: 300px;
background: #ddd;
}
#child {
background: orange;
position: absolute;
top: 50%;
transform: translate(0, -50%);
}
// 2
#box {
width: 300px;
background: #ddd;
padding: 100px 0;
}
#child {
width: 200px;
height: 100px;
background: orange;
}
// 3
#box {
width: 300px;
height: 300px;
background: #ddd;
display: flex;
align-items: center; // Vertical centering
justify-content: center; // Horizontal centering
}
<div id="box">
<div id="child">test vertical align</div>
</div>
Three-Column Layout#
1: Set display: grid for the parent div, set the grid-template-columns property to fix the width of the first and second columns, and auto for the third.
2: Set float: left for the divs, and set overflow: hidden for the right div. This way, the two boxes float, and the other box triggers BFC to achieve adaptability.
<div class="div1"> 1</div>
<div class="div2">2</div>
<div class= "div3"> 3 </div>
.div1,
.div2 {
float: left;
height: 100px;
width: 100px;
background: blue;
}
.div3 {
overflow: auto;
height: 100px;
width: 100px;
background: red;
}
JS Setting Carousel#
The principle of image carousel is that images are arranged in a row, and a container of only one image size is prepared, with overflow hidden set for this container. A timer is controlled to move these images left or right as a whole, thus presenting the effect of image rotation.
If there are two carousels, a carousel component can be encapsulated for two places to call.
Difference Between Link and @import#
- Link is an HTML tag, with no compatibility issues; @import is provided by CSS, recognized only by IE5 and above.
- Link styles have higher weight than @import.
- Link and page load simultaneously, while @import loads only after the page has finished loading.
Difference Between Transition and Animation#
Animation and transition share most properties; they both change the property values of elements over time. Their main difference is that transition requires an event to trigger a change in properties, while animation changes property values over time without needing to trigger any events, and transition consists of 2 frames, from … to, while animation can be frame by frame.
Flex Layout#
Flex is a flexible layout that provides maximum flexibility for box models. Traditional layout methods rely on position, float, and display properties, which are inconvenient for special layouts.
- Container Properties
- flex-direction: Determines the direction of the main axis (i.e., the arrangement method of child items).
- flex-wrap: Determines the wrapping rules.
- justify-content: Alignment method, horizontal main axis alignment method.
- align-items: Alignment method, vertical axis direction.
- Element Properties
- align-self: Allows a single item to have a different alignment than other items, can override align-items, default property is auto, indicating inheritance from the parent element's align-items.
Margin Collapse Problem#
Multiple adjacent (sibling or parent-child) normal flow block elements will collapse vertically in margin.
The result of the collapse is:
When both adjacent margins are positive, the result of the collapse is the larger of the two values.
When both adjacent margins are negative, the result of the collapse is the larger of the absolute values.
When one margin is positive and the other is negative, the result of the collapse is the sum of the two.
.div {
display: flex; // Elements with display: flex; generate BFC
flex-direction: column;
}
// Grouping Selector
.div1,
.div2 {
height: 100px;
width: 100px;
border: 1px solid #000;
margin: 100px;
/* Obviously, the distance between the two borders is not 400, but 200 */
}
BFC#
Function: Used to clear floats, prevent margin overlap, etc.
Block Formatting Context is an independent rendering area with certain layout rules. BFC is an independent container on the page, and child elements will not affect the outside.
The height of BFC will also include floating elements when calculating.
Elements that will generate BFC:
- Root element.
- float: not none.
- position: fixed/absolute.
- display: inline-block, table-cell, table-caption, flex, inline-flex.
- overflow: not visible.
Element Disappearance#
visibility=hidden, opacity=0, display
- opacity=0, the element is hidden but does not change the page layout and can trigger bound events.
- visibility=hidden, the element is hidden, does not change the page layout, and will not trigger bound events.
- display=none, the element is hidden, changes the page layout, and can be understood as deleting the element from the page.
Position Property#
- fixed: Fixed relative to the browser window; it does not move even if the window scrolls, and it is not in the document flow; fixed elements can overlap with other elements.
- relative: Offsets relative to its original position; the element still occupies its original space in the document flow.
- absolute: Positioned relative to the nearest parent element, not in the document flow.
- static: Default value, no positioning, appears in the normal document flow, ignoring any top, bottom, left, right declarations.
- sticky: The element is first positioned according to the normal document flow, then positioned relative to the flow root (BFC) and containing block (the nearest block-level ancestor). A sticky element will be "fixed" to the nearest ancestor with a "scrolling mechanism."
Float Clearing#
In non-IE browsers (like Firefox), when the container's height is auto and there are floating (float: left or right) elements in the container's content, the container's height cannot automatically extend to fit the content's height, causing the content to overflow outside the container and affect (or even destroy) the layout. This phenomenon is called float overflow, and the CSS processing done to prevent this phenomenon is called CSS float clearing.
- Set the CSS overflow to auto.
- Use an empty element, with the CSS clear property set to both.
Block, Inline, Inline-Block Differences#
- Block elements occupy a whole line, and their width automatically fills the parent element's width. The height, width, line height, and top and bottom margins can all be set. Even if a width is set, it still occupies a whole line. For example,
div, p. - Inline elements are arranged in a line until they exceed the width, at which point they will wrap to a new line, and their width changes with the content. Width and height properties are ineffective, and vertical padding and margins will be ineffective. For example,
a, span. - Inline-block: Has both the width and height characteristics of block and the same-line characteristics of inline. For example,
img, input.
CSS Preprocessors#
Pre-compiling and processing CSS. Extends CSS, adding features like variables, mixins, functions, etc., for developers to write source code, which is then converted into CSS syntax through specialized compilation tools.
Features:
• Nesting;
• Variables;
• Mixin/inheritance;
• Calculations;
• Modularization;
Categories and Development:
- 2007, sass-scss (two sets of syntax rules: one still uses indentation to separate code blocks; the other uses curly braces ({}) as separators. The latter syntax is called
SCSS, supported in all versions after Sass3.) - 2009, less (uses
CSSsyntax). - 2010, Stylus (supports both indentation and standard CSS writing rules).
HTML5#
New Elements#
Semantic: header, footer, nav, aside, article, section.
Storage: sessionStorage, localStorage.
Multimedia: audio, video.
Drawing: svg, canvas, webgl.
Communication: websocket.
Multithreading: web worker.
Operating Systems#
Processes and Threads#
Process#
The smallest unit of system call resources, meaning it is the smallest unit that has resources and runs independently.
Thread#
The smallest unit of CPU scheduling. A process can have multiple threads, and a thread is the smallest unit that can run independently.
Process Switching Overhead#
- Switch virtual address space.
- Switch CPU context.
- Switch kernel stack.
Thread Switching Overhead#
- Switch CPU context.
- Switch kernel stack.
Process Communication#
- Pipe.
- Message queue.
- Semaphore.
- Signal.
- Socket.
- Shared memory.
JS#
Data Types#
- 6 primitive types, which can be judged using typeof:
- undefined.
- Number.
- Boolean.
- String.
- Symbol.
- BigInt: BigInt is created by appending
nto the integer or calling the constructor.
- null, which belongs to the above six primitive values.
- Object:
- Array.
- Map.
- WeakMap.
- Set.
- WeakSet.
- Date.
Differences Between Basic Data Types and Reference Types#
- Basic Data Types
String, Number, Boolean, Null, Undefined
Fixed space occupancy, stored in the stack.
Saves and copies the value itself.
Uses typeof to detect the type of data.
- Reference Types
Object, Array, Function
Variable space occupancy, stored in the heap.
Saves and copies a pointer to the object.
Uses instanceof to detect the data type.
Object#
-
Object.keys(), gets own properties.
-
for in traverses extended properties on the prototype chain.
-
Object.create()method creates a new object, using an existing object to provide the__proto__of the newly created object. -
Object.assign()method is used to copy all enumerable property values from one or more source objects to a target object. It returns the target object.
Object.assign(target, ...sources) => target
const target = { a: 1, b: 2 };
const source = { b: 4, c: 5 };
const returnedTarget = Object.assign(target, source);
console.log(target);
// expected output: Object { a: 1, b: 4, c: 5 }
console.log(returnedTarget);
// expected output: Object { a: 1, b: 4, c: 5 }
Object.defineProperties()method directly defines new properties or modifies existing properties on an object and returns that object.
Object.defineProperties(obj, props)
Array Methods#
Modifying#
- push, unshift, modifies in place.
- pop, shift, modifies in place.
- splice, modifies in place, (index, num, val1, val2, …).
Sorting#
- sort, modifies in place.
Slicing Subarrays#
- slice, returns a new array.
Merging Arrays#
- concat, merges two or more arrays. This method does not change existing arrays but returns a new array.
var new_array = old_array.concat(value1[, value2[, ...[, valueN]]])
Flat#
flat()method recursively traverses an array according to a specified depth and merges all elements with the elements in the traversed subarrays into a new array to return.
Join#
join()method joins all elements of an array (or an array-like object) into a string and returns that string. If the array has only one item, it will return that item without using a separator.
Traversing#
-
forEach, traverses the array, does not return a new array, and cannot exit early.
-
map, processes elements and returns a new array of processed results.
-
reduce, returns a new array.
Testing#
filter()method creates a new array containing all elements that pass the test implemented by the provided function.
var newArray = arr.filter(callback(element[, index[, array]])[, thisArg])
- every, tests whether all elements in an array pass a specified function's test. It returns a boolean value. If an empty array is received, this method will return
truein all cases.
arr.every(callback(element[, index[, array]])[, thisArg])
-
some()method tests whether at least one element in the array passes the provided function's test. It returns a Boolean value. -
findmethod executes thecallbackfunction on each element in the array until one callback returnstrue. When such an element is found, this method immediately returns the value of that element; otherwise, it returnsundefined. -
findIndex()method returns the index of the first element in the array that satisfies the provided testing function. If no corresponding element is found, it returns -1. -
indexOf()method returns the first index at which a given element can be found in the array, or -1 if it is not present. -
includes()method determines whether an array contains a specified value, returning true if it does, and false otherwise.
ES6 New Features#
- In variable declaration: let, const.
- Object-oriented programming has syntax sugar class.
- In module import: import export.
- New data structures: map, set.
- New array methods: map, reduce.
- Asynchronous: promise.
- Arrow functions.
- Destructuring assignment and spread operator.
- Etc...
Asynchronous#
Async, Promise, and Generator, What Are the Differences?#
-
Generator functions block the function in steps, and the next step can only be executed by actively calling next().
-
The
asyncandawaitkeywords allow us to write asynchronous behavior based onPromisein a more concise way without deliberately chainingpromise.
Async functions may contain 0 or more await expressions. The await expression will pause the execution of the entire async function and relinquish control until the awaited promise-based asynchronous operation is fulfilled or rejected. The resolved value of the promise will be treated as the return value of that await expression. Using async / await allows us to use regular try / catch blocks in asynchronous code.
Async functions always return a promise object. If the return value of an async function does not seem to be a promise, it will be implicitly wrapped in a promise.
The behavior of async/await is similar to using generators and promises together.
Promise#
Three States#
Pending, fulfilled, rejected.
Static Methods#
Promise.all(iterable)#
@ para: Array of promises or iterable.
@ return: If successful, returns an array of all promise return values; if it fails, it takes the error message of the first promise object that triggers failure as its failure error message.
Compared to allSettled, all is more suitable for mutually dependent promises or when any reject occurs, it ends immediately.
Promise.allSettled(iterable)#
Returns a promise that resolves after all given promises have either been fulfilled or rejected, with an array of objects that each describe the outcome of each promise.
This is typically used when you have multiple independent asynchronous tasks that you want to know the result of each promise.
Promise.any(iterable)#
Receives a collection of Promise objects and returns the value of the first promise that succeeds. The fastest successful one.
Promise.race(iterable)#
Returns a promise that resolves or rejects as soon as one of the promises in the iterable resolves or rejects. That is, the fastest one to process, whether successful or failed.
Promise.reject(reason)#
Returns a Promise object that is rejected with the given reason.
Promise.resolve(value)#
Returns a Promise object that is resolved with the given value.
If the value is a promise, it will return the promise that is executed;
If the value is thenable (i.e., has a then method), the returned promise will "follow" the thenable object and adopt its eventual state; otherwise, the returned promise will be fulfilled with that value.
This function flattens nested promise-like objects.
Implementing Promise#
// Define three states
const PENDING = 'PENDING'; // In progress
const FULFILLED = 'FULFILLED'; // Successfully
const REJECTED = 'REJECTED'; // Failed
class Promise {
constructor(exector) {
// Initialize state
this.status = PENDING;
// Store success and failure results on this for access in then and catch
this.value = undefined;
this.reason = undefined;
const resolve = (value) => {
// Only change state if in progress
if (this.status === PENDING) {
this.status = FULFILLED;
this.value = value;
}
};
const reject = (reason) => {
// Only change state if in progress
if (this.status === PENDING) {
this.status = REJECTED;
this.reason = reason;
}
};
// Immediately execute exector
// Pass the internal resolve and reject to the executor, allowing the user to call resolve and reject
exector(resolve, reject);
}
then(onFulfilled, onRejected) {
// then is a microtask, here simulated with setTimeout
setTimeout(() => {
if (this.status === FULFILLED) {
// Execute only in FULFILLED state
onFulfilled(this.value);
} else if (this.status === REJECTED) {
// Execute only in REJECTED state
onRejected(this.reason);
}
});
}
}
Implementing All#
var all = (promises) => {
if (!Array.isArray(promises)) {
return reject(new TypeError('arguments must be an array'));
}
var l = promises.length;
var result = new Array(l);
var num = 0;
return new Promise((resolve) => {
for (let i = 0; i < l; i++) {
Promise.resolve(promises[i]).then(
(res) => {
result[i] = res;
num += 1;
if (num === l) {
return resolve(result);
}
},
(reason) => {
return reject(reason);
}
);
}
});
};
This#
The this in a function refers to the caller;
In strict mode, at the global top level, it is undefined.
Arrow Functions#
Purpose: Shorter functions that do not bind this.
Cannot be used as constructors and do not have their own prototype property;
No arguments, but can use the spread operator to obtain the rest parameters.
Symbol#
Each symbol value returned from Symbol() is unique. A symbol value can be used as an identifier for object properties; this is the only purpose of this data type.
Syntax not supported: "new Symbol()".
Object.getOwnPropertySymbols() method allows you to return an array of symbol properties when looking up the symbol properties of a given object.
Set#
Set: An array with unique member values (i.e., a collection).
// Instances of Set structure have the following properties.
Set.prototype.constructor: The constructor, which defaults to the Set function.
Set.prototype.size: Returns the total number of members in the Set instance.
// The methods of Set instances can be divided into two categories: operation methods (for manipulating data) and traversal methods (for iterating over members). Below are four operation methods.
Set.prototype.add(value): Adds a value, returning the Set structure itself.
Set.prototype.delete(value): Deletes a value, returning a boolean indicating whether the deletion was successful.
Set.prototype.has(value): Returns a boolean indicating whether the value is a member of the Set.
Set.prototype.clear(): Clears all members, with no return value.
WeakSet structure is similar to Set, also a collection of non-repeating values.
WeakSet members can only be objects, not other types of values.
Additionally, objects in WeakSet are weak references, meaning the garbage collection mechanism does not consider WeakSet's reference to that object.
Map#
A Map structure only considers references to the same object as the same key. However, for numerical and string values, it has no effect.
The keys of Map are actually bound to memory addresses; as long as the memory addresses are different, they are considered two keys. This solves the problem of name collisions.
Note: If the key of a Map is a simple type value (number, string, boolean), then as long as the two values are strictly equal, Map considers it as one key; for example, 0 and -0 are one key, while the boolean value true and the string true are two different keys.
Additionally, undefined and null are also two different keys. Although NaN is not strictly equal to itself, Map considers it as the same key.
You can iterate over all elements in the order they were inserted.
- new Map(), or initialized like this:
new Map([['foo', 3], ['bar', {}], ['baz', undefined]]) - Map.prototype.set(k, v)
- Map.prototype.delete(k), deletes.
- Map.prototype.clear(), clears the map.
- Map.prototype.get(k), for v being a reference type, you can modify it in place on the return value (but cannot assign directly); if it is a basic type, you still need to use set to modify.
- Map.prototype.has(k)
- Map.prototype.size, gets the size.
- for (var [key, value] of mapObj), iterates.
- Map.prototype.forEach((v, k, map) => {}), iterates in insertion order, performing an operation on each element.
- Map.prototype.keys()
- Map.prototype.values()
- Map.prototype.entries()
Proxy#
Proxy sets up a layer of "interception" in front of the target object, and all external access to that object must pass through this layer of interception, where external access can be filtered and rewritten.
// new Proxy() indicates generating a Proxy instance, target parameter indicates the target object to be intercepted, handler parameter is a configuration object used to customize interception behavior. For each operation to be proxied, a corresponding handling function must be provided.
var proxy = new Proxy(target, handler);
var proxy = new Proxy(
{},
{
get: function (target, propKey) {
// The get method's two parameters are the target object and the property to be accessed.
return 35; // Since the interceptor function always returns 35, accessing any property will yield 35.
},
}
);
proxy.time; // 35
proxy.name; // 35
proxy.title; // 35
// If handler === {}
Can be inherited, meaning Proxy instances can serve as the prototype object for other objects.
var proxy = new Proxy(
{},
{
get: function (target, propKey) {
return 35;
},
}
);
let obj = Object.create(proxy);
obj.time; // 35
Scope#
script, function, {}#
-
Variables declared with var, let, const in script are global variables.
-
Variables declared with var, let, const in function are local variables, only usable within that function and lower-level functions (can be output externally using closures).
-
Variables declared in {} with var are still global variables, but let, const are local variables and cannot be used outside.
Note: The difference between for (var i = 0; i < n; i++) and for (let i = 0; i < n; i++) is that var defines a global variable within for, while let defines n local variables within for.
To use var in an asynchronous function within for with different values, use closures, i.e., declare a new function inside for (which can be without related parameters) and use it.
Global Scope#
A variable (var, let, const) declared outside a function or outside the curly braces {} defines a variable in the global scope. Once you declare a global variable, you can use it anywhere, even inside functions.
Local Scope#
In JavaScript, there are two types of local scopes: function scope and block scope.
Function Scope#
When you declare a variable (var, let, const) inside a function, you can only use it within that function's scope. You cannot use it outside that scope.
Block Scope#
When you use const or let to declare a variable within a set of curly braces {}, that variable can only be used within that block's scope.
Nested/Lexical Scope#
When a function is defined inside another function, the inner function can access the outer function's variables (this is the principle of closure). We call this lexical scope. However, the outer function cannot access the inner function's variables.
Closure#
Definition#
A closure is a combination of a function and a reference to its surrounding state (lexical environment) (or a function being enclosed).
In other words, closures allow you to access the scope of an outer function from an inner function. In JavaScript, every time a function is created, a closure is created alongside it.
Declare an inner function within a function and return it (or as a property of the returned object).
A closure is a function that can read other functions' internal variables, or a child function that can be called externally, and the scope of the parent function where the child function resides will not be released.
Principle#
The inner function can access the outer function's variables, exposing the outer function's variables when the closure is returned.
Uses#
Solving Side Effects#
By creating a function when you want to activate the internal closure.
function prepareCake(flavor) {
return function () {
setTimeout((_) => console.log(`Made a ${flavor} cake!`), 1000);
};
}
const makeCakeLater = prepareCake('banana');
// And later in your code...
makeCakeLater();
// Made a banana cake!
Using Private Variables in Closures#
function secret(secretCode) {
return {
saySecretCode() {
console.log(secretCode);
},
};
}
const theSecret = secret('CSS Tricks is amazing');
theSecret.saySecretCode();
// 'CSS Tricks is amazing'
Solving the Issue of Var Global Variables Changing in Asynchronous Function Calls#
for (let i = 0; i < 5; i++) {
setTimeout(() => {
console.log(i);
}, 1000 * i);
}
// Output: 0 1 2 3 4
for (var i = 0; i < 5; i++) {
setTimeout(() => {
console.log(i);
}, 1000 * i);
}
// Output: 5 5 5 5 5, 5 is because the last i++ jumps out to 5
// Using closure to achieve a similar result to let
for (var i = 0; i < 5; i++) {
function f(i: number) {
setTimeout(() => {
console.log(i);
}, 1000 * i);
}
f(i);
}
// Output: 0 1 2 3 4
Prototype#
Prototype Definition#
- Objects have the property
__proto__, which points to the prototype object of the constructor that created that object. - Methods have the property
prototype, which points to the prototype object of that method.
In JS, everything is an object. Methods (Functions) are objects, and the prototype of methods (Function.prototype) is also an object. Therefore, they share the characteristics of objects.
That is: Objects have the property proto, which can be called the implicit prototype. An object's implicit prototype points to the prototype of the constructor that constructed that object, which ensures that instances can access properties and methods defined in the constructor's prototype.
This special object, the method, has the above-mentioned proto property, but also has its own unique property - the prototype property (prototype), which is a pointer to an object whose purpose is to contain all properties and methods shared by instances (we call this object the prototype object). The prototype object also has a property called constructor, which contains a pointer that points back to the original constructor.
JavaScript is often described as a prototype-based language - every object has a prototype object, and objects inherit methods and properties from their prototypes.
Prototype objects may also have prototypes and inherit methods and properties from them, layer by layer, and so on. This relationship is commonly referred to as the prototype chain, which explains why an object has properties and methods defined in other objects. The prototype object is an internal object and should be accessed using __proto__.
Accurately speaking, these properties and methods are defined on the constructor function's prototype property, not on the object instance itself.
// Function
function doSomething(){}
console.log( doSomething.prototype );
// Output:
{
constructor: ƒ doSomething(),
__proto__: {
constructor: ƒ Object(),
hasOwnProperty: ƒ hasOwnProperty(),
isPrototypeOf: ƒ isPrototypeOf(),
propertyIsEnumerable: ƒ propertyIsEnumerable(),
toLocaleString: ƒ toLocaleString(),
toString: ƒ toString(),
valueOf: ƒ valueOf()
}
}
doSomething.prototype.foo = "bar";
{
foo: "bar",
constructor: ƒ doSomething(),
__proto__: {
constructor: ƒ Object(),
hasOwnProperty: ƒ hasOwnProperty(),
isPrototypeOf: ƒ isPrototypeOf(),
propertyIsEnumerable: ƒ propertyIsEnumerable(),
toLocaleString: ƒ toLocaleString(),
toString: ƒ toString(),
valueOf: ƒ valueOf()
}
}
var doSomeInstancing = new doSomething();
doSomeInstancing.prop = "some value"; // add a property onto the object
{
prop: "some value",
__proto__: {
foo: "bar",
constructor: ƒ doSomething(),
__proto__: {
constructor: ƒ Object(),
hasOwnProperty: ƒ hasOwnProperty(),
isPrototypeOf: ƒ isPrototypeOf(),
propertyIsEnumerable: ƒ propertyIsEnumerable(),
toLocaleString: ƒ toLocaleString(),
toString: ƒ toString(),
valueOf: ƒ valueOf()
}
}
}
The prototype object is an internal object and should be accessed using __proto__. The __proto__ property of doSomeInstancing is doSomething.prototype.
When you access a property of doSomeInstancing, the browser first checks whether doSomeInstancing has that property. If doSomeInstancing does not have that property, the browser will look for that property in doSomeInstancing's __proto__ (which is doSomething.prototype). If doSomeInstancing's __proto__ has that property, then the property on doSomeInstancing's __proto__ will be used.
Otherwise, if doSomeInstancing's __proto__ does not have that property, the browser will look for that property in doSomeInstancing's __proto__'s __proto__, and so on.
By default, the __proto__ of all function prototype properties is window.Object.prototype. Therefore, doSomeInstancing's __proto__'s __proto__ (which is doSomething.prototype's __proto__ (which is Object.prototype)) will be checked for that property. If that property is not found in it, the browser will conclude that this property is undefined.
Finally, all __proto__s on the prototype chain are checked, and if the property is not found on any of the already declared __proto__s, it concludes that the property is undefined.
Inheritance#
JavaScript inheritance of object functions is not done through copying but through prototype chain inheritance (commonly referred to as prototypal inheritance).
By using function.call to call the parent class's constructor, but this cannot automatically set the value of Child.prototype, so Child.prototype can only contain properties constructed in the constructor, without methods.
Therefore, we use Object.create() method to make Parent.prototype the prototype object of Child.prototype, and change its constructor pointer to associate it with Child.
Now the prototype of the subclass's constructor property points to the parent class, and we need to change it back to the Child.
function Parent(x1) {
this.x1 = x1;
this.f1 = function () {
console.log('parent!');
};
}
// New constructor
function Child(y1, x1) {
Parent.call(this, x1);
this.y1 = y1;
this.f1 = function () {
console.log('Child!');
};
}
// Default has an empty prototype property, allowing Child() to inherit methods from Parent()'s prototype object
Child.prototype = Object.create(Parent.prototype);
// Now Child()'s prototype's constructor property points to Parent(), change it back to Child
Child.prototype.constructor = Child;
let cObj = new Child(2, 1);
ES6#
class c2 extends c1 {}
class Point {
constructor(x, y) {
this.x = x;
this.y = y;
}
toString() {
return '(' + this.x + ', ' + this.y + ')';
}
}
typeof Point; // "function"
Point === Point.prototype.constructor; // true, the data type of the class is a function, and the class itself points to the constructor. When using it, it is directly used with the new command, which is completely consistent with the usage of constructors.
class ColorPoint extends Point {
constructor(x, y, color) {
this.color = color; // ReferenceError
super(x, y);
this.color = color; // Correct
}
}
Event Loop#
In the task queue, in each event loop, a macrotask will only extract one execution, while microtasks will keep extracting until the microtask queue is empty.
This means that if a microtask is pushed into execution, when the main thread task execution is complete, it will loop to call the next task in that queue to execute until the last task in that task queue is reached.
The event loop only pushes one macrotask onto the stack each time; after the main thread completes that task, it checks the microtasks queue and completes all tasks in it before executing the macrotask.
- Macrotasks: setTimeout, setInterval, setImmediate, I/O, UI rendering.
- Microtasks: process.nextTick, Promise, MutationObserver.
Event Delegation#
Instead of setting the listener function directly on the event's occurrence location (the direct DOM), set the listener function on its parent element. Through event bubbling, the parent element can listen to the triggering of events on child elements and respond differently by judging the type of DOM where the event occurred.
Event Listening#
Element.addEventListener(event, func, useCapture)
The first parameter is the type of event (such as "click" or "mousedown").
The second parameter is the function to be called when the event is triggered.
The third parameter is a boolean used to describe whether the event is executed in the capturing or bubbling phase. This parameter is optional.
Event propagation has two ways: bubbling and capturing.
Event propagation defines the order of element event triggering. If you insert element P into element div, when the user clicks element P,
In bubbling, the inner element is triggered first, then the outer element is triggered.
In capturing, the outer element is triggered first, then the inner element.
Image Lazy Loading and Preloading#
Preloading: Load images in advance so that when users need to view them, they can be rendered directly from local cache.
Lazy loading: The main purpose of lazy loading is to optimize the server front end, reducing the number of requests or delaying the number of requests.
Difference Between Mouseover and Mouseenter#
mouseover: The event will be triggered when the mouse enters the element or its child elements, causing a repeated triggering and bubbling process. The corresponding removal event is mouseout.
mouseenter: The event will be triggered when the mouse leaves the element itself (excluding child elements), meaning it does not bubble. The corresponding removal event is mouseleave.
What Does New Do?#
-
The new operator creates an empty object, and this object's
__proto__points to the constructor'sprototype. -
Executes the constructor and returns this object.
Drag-and-Drop Functionality#
Three events: mousedown, mousemove, mouseup.
Two coordinates, clientX, clientY represent the mouse coordinates, indicating horizontal and vertical coordinates, and we use offsetX and offsetY to represent the initial coordinates of the element.
Dragging is done under absolute positioning, and we change the values of left, top, etc., under absolute positioning conditions.
Debouncing#
The event is triggered n seconds later to execute the callback; if triggered again within these n seconds, the timer resets.
Usage scenarios:
- Button submission: Only execute the last submission to prevent multiple submissions.
- Search box suggestions: Prevent suggestions from sending